The Construction of Object Swap
Although many studies have explored text-guided video inpainting, such as AVID and COCOCO, most of these methods rely on outdated video foundation models, such as AnimateDiff. Consequently, the generated videos often exhibit noticeable artifacts and inconsistencies. Recently, Hu et al. proposed the VIVID model, which trains an inpainter based on CogVideoX-5B-I2V. Unfortunately, their inpainter has not been open-sourced. Similar with the methods proposed by Hu et al., we use the first-frame edited by a stable and well-performed image editor Flux-Fill to guide the inpainting process.
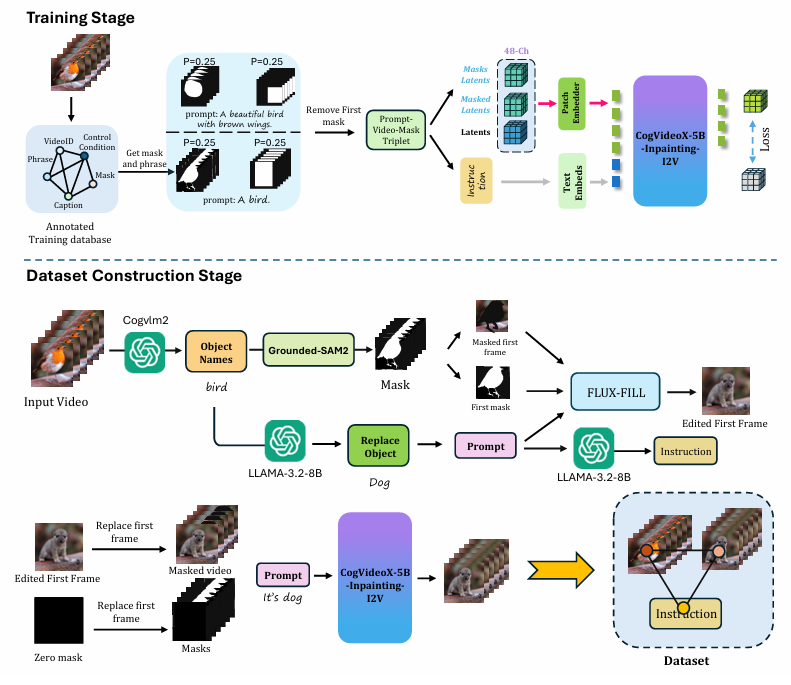
The difference between VIVID and our inpainter lies in the following aspects. For training mask selection, we employ masks with random positions and shapes. We observed that the model tends to overfit to specific mask shapes during inpainting. To mitigate this, we generate masks with either random shapes or rectangles with varying aspect ratios in the first frame and periodically shift their locations in the subsequent frames. For both types of masks, we use video captions as prompts. Additionally, we introduce object-covering masks to enhance the model’s learning capacity. These masks are categorized into two types: (1) precise masks detected by Grounded-SAM2 and (2) rectangular masks expanded from these precise masks. These masks are paired with structured prompts, which consist of pronouns and detected phrases, for training. Further details are provided in Figure. Another key difference is in patch embedder initialization. Specifically, we initialize the first 16 channels of the patch embedder using parameters from the original patch embedders, while the remaining channels are zero-initialized.
For training, we set the first frame of the mask sequence to zeros to utilize the guidance of the edited image. The inpainter is initialized with the parameters of CogVideoX-5B-I2V. Unlike global stylizer methods, our inpainter does not require a control branch, allowing for a larger batch size. We trained for 1 epoch on our expert dataset with AdamW optimizer, batch size of 16 and a learning rate of 1e-5. The resolution used during training was 336 x 592, and the number of frames was 33, the stride is 2. We freeze all FFN layers except for the first DiT block.
During inference, we input the prepared prompts, dilated precise masks, and videos to generate the inpainted video. The first frame is edited by Flux-Fill with a new object name. The new object name are generated by LLM. We use the classifier-free guidance of 6. The inference process can be finished on an Nvidia RTX 4090 GPU within 2 minutes, 33 frames and resolution of 336 x 592.