The Construction of the Local Stylization
Inspired by SparseControl, CoCoCo, and AVID, we trained a local stylizer by combining both inpainting and ControlNet, enabling appearance modification, stylization, and texture manipulation in specific regions of videos, while keeping the original background unchanged.
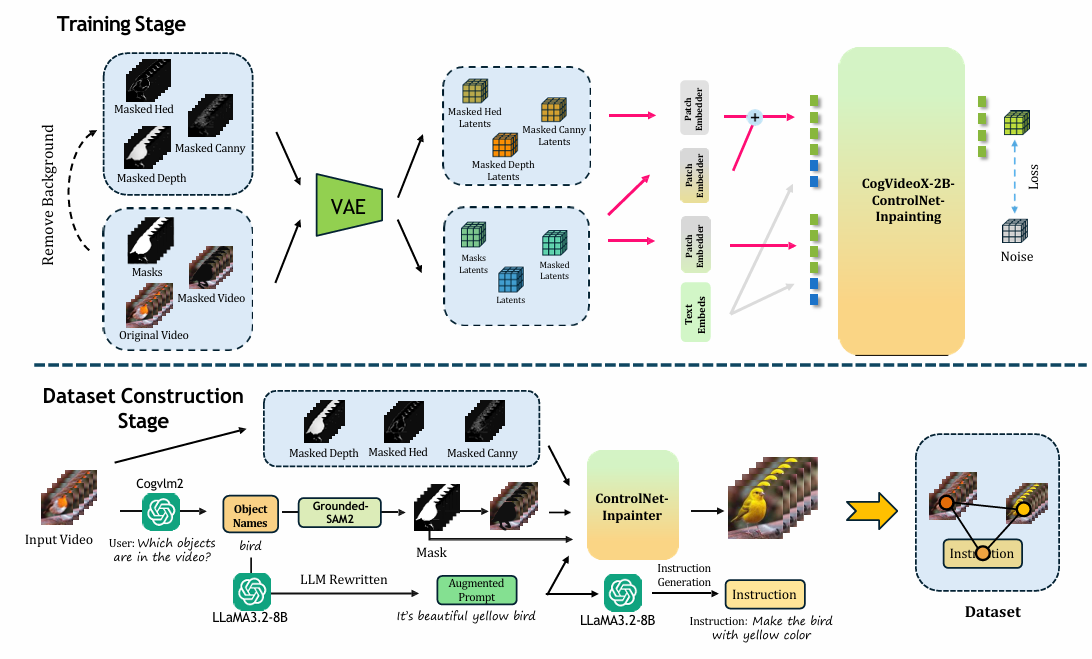
We use the same controlnet architecture as in our gloabl stylizer. The difference between two models mainly lies in the base model and input condition. For our local stylizer, we utilize the CogVideoX-2B model as the base. As shown in Figure, the main branch takes the original video latents, masked video latents, and mask latents as input (48 channels). To mitigate the inflated channel dimension, we initialize our patch embedder using the first 16 channels from CogVideoX-2B, while the remaining 32 channels are zero-initialized. Similarly, the patch embedder for control branch are also zero-initialized.
Our control branch consists of 6 DiT blocks copied from main branch. For training data, we use the mask and phrases in the training dataset. We then combine the phrase with some pronouns randomly, to compose them as a sentence for training. We trained our local stylizer for 1 epoch, with a batch size of 32, AdamW optimizer, a learning rate of 1e-5, and a weight decay of 1e-4. The training videos consist of 33 frames at a resolution of 336 x 592. Similarly, to preserve generalization ability and accelerate training, we freeze the FFN layers except for the first DiT block.
For inference, we use a classifier-free guidance scale of 6. The inference process completes within 1 minute on an Nvidia RTX 4090 for a video with a resolution of 336 x 592, the length is 33. We prepend the sentence prefix "It's" to the detected object phrase and pronouns to form a complete prompt. For example, when we want to paint the house in the video to yellow, we should use the prompt: "It's a yellow house."