The Construction of the Object Remover
Traditional video inpainter, such as Propainter, uses optical flow to guide the completion. However, these methods show weaker performance than diffusion model. Inpainters, such as CoCoCo, AVID are designed to add objects. Recently, a new inpainting method, namely VIVID are designed to add, modify and remove video objects. We fully explored the CoCoCo and found it performs bad on object removal, since it has a high percentage to generate the object in the masked region, similar to the mask shape. To overcome this drawback, we design a training paradigm to break the correlation between generated content and mask shape.
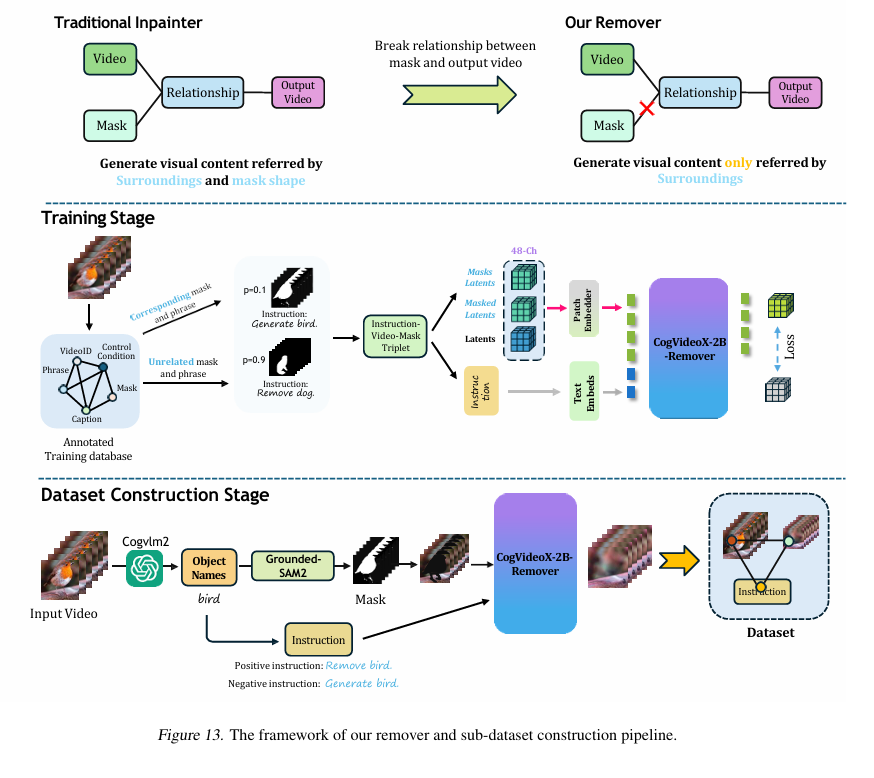
As shown in Figure, our remover is trained by assuming that the input video contains objects from unrelated videos. The model is provided with an arbitrary mask from another video and learns to remove the assumed object while generating the object in the input video. Specifically, we randomly sample a mask and phrase from other video and used this mask to remove regions from the given video. We take 90% unrelated masks with instruction "Remove {object name}", and 10% masks corresponding to the input videos with instruction "Generate {object name}". This can be viewed as we use mask and the generate instruction corresponding to the input video as negative condition. During inference, the classifier-free guidance will steer the generation away from the negative condition, thus achieving the object removal.
We train the remover on our expert dataset for 1 epoch with AdamW optimizer, a batch size of 32, a learning rate of 1e-5, and a weight decay of 1e-4. For data sampling, we selected 90% of the samples as task-irrelevant masks and 10% as task-relevant masks. The video was sampled at 33 frames with a stride of 2, and the resolution was set to 336 x 592. Our Remover is built upon the CogVideoX-2B model and initialized with its pre-trained parameters. Similarly, to preserve generalization ability and accelerate training, we freeze the FFN layers except for the first DiT block.
During inference, we use classifier-free guidance scale of 2, the positive prompt is "Remove {object name}", while the negative prompt is "Generate {object name}". The frame number is 33 and the resolution of 336 x 592. The removal process can be finished within 1 minute on an Nvidia RTX 4090 GPU.