The Construction of the Global Stylization
We find that two powerful video generation models, i.e., CogVideoX and HunyuanVideo, lack sufficient ability to generate videos that accurately follow style information. This limitation prevents us from applying techniques such as ControlNet to repaint a video effectively. To address this, we shift our focus to image-based ControlNet to leverage the strong stylization capabilities of these models, enhancing the stylization of video generation. Specifically, we first apply an image ControlNet to process the first frame, then use a video ControlNet to propagate the style across the remaining frames. Since video generation models inherently maintain temporal consistency between frames, the style applied to the first frame can be effectively transferred to the rest of the video.
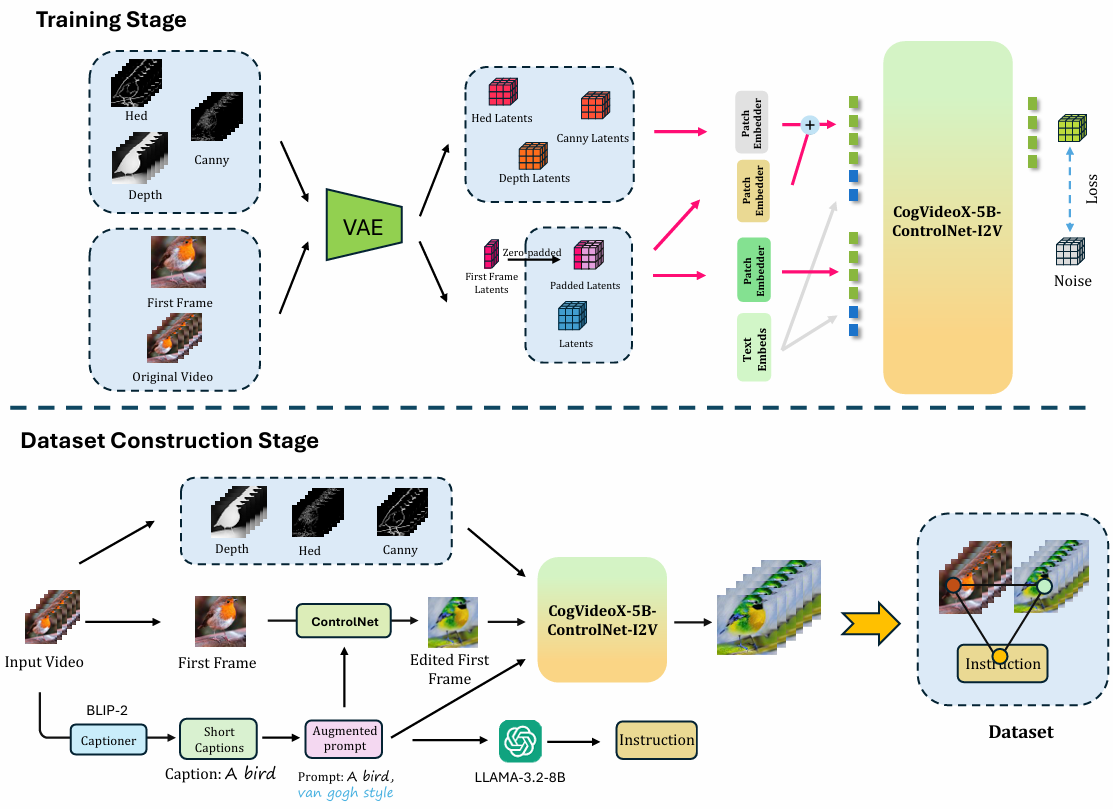
We utilize the architecture of ControlNet for DiT and integrate it with CogVideoX-5B-I2V to process subsequent frames, maintaining the video's structure consistently propagate the style from the first frame. Specifically, we inject first frame features from the control branch (ControlNet) into the main branch (base model) through zero convolution. The control branch consists of N layers, while the main branch has M layers, with M being a multiple of N. We ensure that once the first N layers of the main branch have been added with hidden states, the K-th layer of the main branch receives the K%N-th hidden state from the control branch. This process is repeated until all DiT blocks in the main branch have received the control hidden states.
For the input to the DiT block in the transformer, we use two types of patch embedders. In the main branch, the patch embedder processes the input video condition. The control branch uses two patch embedders: the main patch embedder and the control patch embedder, to receive and process the control condition. The output embeddings of both embedders are combined and fed into the model. As shown in Figure, we pad the first frame along the frame dimension and concatenate it with the original latent representation along the channel dimension (32 channels) as input to the main branch. In the control branch, we concatenate the HED, Canny, and depth latents representations along the channel dimension (48 channels).
For training, the parameters of the main branch are initialized using CogVideoX-5B-I2V, and the control branch is copied from the main branch, except for the control patch embedder, which is zero-initialized. We select the first 6 DiT blocks from the main branch to serve as the control branch. We trained our global stylizer on our expert dataset for 1 epoch with a batch size of 8, learning rate of 1e-5, and weight decay of 1e-4. We freeze some training layers to reduce the training cost and keep generalization. Specifically, the norm and FFN layers in the backbone were frozen, while the first DiT block in the control branch was trained. Only the first DiT block, patch embedder, and attention layer in the control branch were trained. We train our global stylizer in two phases. In Phase 1, we train the global stylizer on videos with a resolution of 256 x 448 x 33. Additionally, we incorporate a 10% null prompt during training to enable classifier-free guidance. In Phase 2, we finetuned the model from Phase 1, increasing the spatial resolution to 448 x 896.
During inference, we append the required style prompt to the end of the video description, creating a new combined prompt. The first frame is generated by ControlNet-SD1.5, which is then fed into the model along with the prompt and control condition. We use the classifier-free guidance of 4. The model processes a video within 2 minutes on an Nvidia RTX 4090, at a resolution of 336 x 592, producing 33 frames.