Señorita-2M : A High-Quality Instruction-based Dataset for General Video Editing by Video Specialists
Bojia Zi 1, *, Penghui Ruan 2, *, Marco Chen 3, Xianbiao Qi †4, Shaozhe Hao 5, Shihao Zhao 5, Youze Huang 6, Bin Liang 1, Rong Xiao 4, Kam-Fai Wong 1
1The Chinese University of Hong Kong
2The Hong Kong Polytechnic University
3Tsinghua University
4IntelliFusion Inc.
5The University of Hong Kong
6University of Electronic Science and Technology of China
* is equal contribution †is the corresponding author.
Add a hat on her head.
Make it oil painting style.
Make the narcissus pink.
Add a hat on her head.
Remove the girl and shadow.
Make it anime style.
Remove the bird.
Transform dog into lion.
Make it watercolor style.
Add rainbow.
Models Trained on Senorita-2M Has Strong Generalization for Complex Editing Tasks.
Multi-Region Editing
Paint the bird on the left yellow and the bird on the right pink.
Add a hat to the cat's head and a Christmas tree next to it.
Remove two ducks.
Delete the flower on the left and add a butterfly to the flower on the right.
Shape/Size Editing
Turn pyramid into a sphere.
Replace the pyramid with a sphere.
Turn the goose into a bigger one.
Turn the house into a bigger one.
Motion Editing
Make the cat's head lower.
Make the seal crawl.
Let the squirrel to look left.
Let the swan spread its wings and swimming towards the left.
Abstract
Video content editing has a wide range of applications. With the advancement of diffusion-based generative models, video editing techniques have made remarkable progress, yet they still remain far from practical usability. Existing inversion-based video editing methods are time-consuming and struggle to maintain consistency in unedited regions. Although instruction-based methods have high theoretical potential, they face significant challenges in constructing high-quality training datasets - current datasets suffer from issues such as editing correctness, frame consistency, and sample diversity. To bridge these gaps, we introduce the Señorita-2M dataset, a large-scale, diverse, and high-quality video editing dataset. We systematically categorize editing tasks into 2 classes consinsting of 18 subcategories. To build this dataset, we design four new task specialists and employ or modify 14 existing task experts to generate data samples for each subclass. In addition, we design a filtering pipeline at both the visual content and instruction levels to further enhance data quality. This approach ensures the reliability of constructed data. Finally, the Señorita-2M dataset comprises 2 million high-fidelity samples with diverse resolutions and frame counts. We trained multiple models using different base video models, \ie Wan2.1 and CogVideoX-5B, on Señorita-2M, and the results demonstrate that the models exhibit superior visual quality, robust frame-to-frame consistency, and strong instruction following capability.
Method
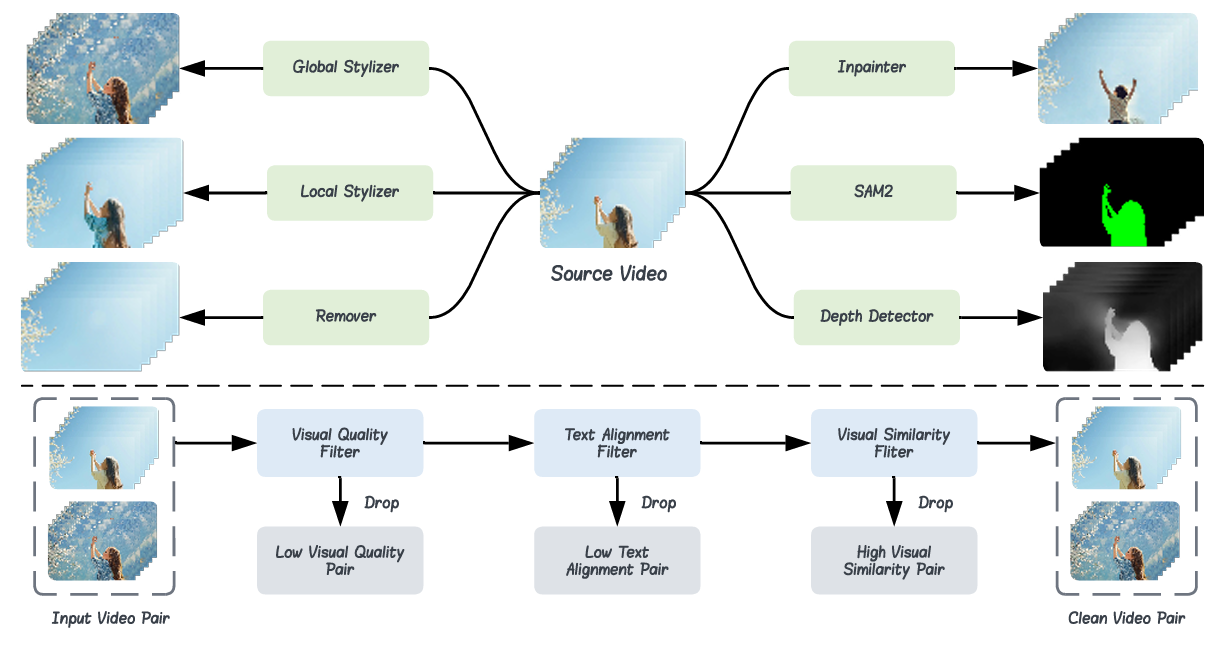
We introduce the high-quality Señorita-2M dataset for training instruction-based editing models, which is diverse, reliable, and faithful. It contains 2 million high-fidelity samples of source and target videos with corresponding instructions, featuring diverse resolutions, frame counts, and has been open-sourced. We systematically categorize editing tasks into 2 broad classes and 18 subcategories to ensure diversity. For each subcategory, we design specialized specialists to generate samples individually, guaranteeing data reliability. Additionally, a filtering pipeline is developed to further enhance reliability. Our dataset enables training of extremely high-quality video editors across different base models. The resulting model exhibits superior visual quality, robust frame-to-frame consistency, and strong alignment with text instructions.
Visualization of Señorita-2M
Swap the bear for cat.
Replace the girl by boy.
Transform the fountain into sculpture.
Make th old man to old lady.
Object Swap
Remove the girl.
Omit the bird.
Wipe out the plant.
Remove the giraffe.
Object Removal
Add cloud.
Add flower.
Add a girl.
Add the flower.
Object Addition
Make this controller pink.
Turn champagne yellow.
Make the trees green.
Make the plant yellow.
Object Stylization
Make it Van Gogh style.
Make it french art style.
Make it cyber punk style.
Make it watercolor style.
Style Transfer
Citation
@inproceedings{zi2025senorita, title={Señorita-2M: A High-Quality Instruction-based Dataset for General Video Editing by Video Specialists},
author={Bojia Zi and Penghui Ruan and Marco Chen and Xianbiao Qi and Shaozhe Hao and Shihao Zhao and Youze Huang and Bin Liang and Rong Xiao and Kam-Fai Wong},
booktitle={NeurIPS D&B},
year={2025},
}